In January 2024 I presented with Kaspar Beelen at a virtual Research Colloquium on Digital History at the Humboldt-Universität zu Berlin / Forschungskolloquiums "Digital History" an der Humboldt-Universität zu Berlin: 'Das interdisziplinär ausgerichtete Projekt untersuchte mithilfe von Machine-Learning-Ansätzen den Einfluss der industrielle Revolution und insbesondere der Technologien auf das menschliche Leben anhand verschiedener Quellenkorpora, wie digitalisierten Zeitungen, Volkszählungen oder Karten.' The video is online.
I also gave a talk online for the Home Office's Data & Information Week with Karen Tingay (Head of Data and Methods, Office for Statistics Regulation).
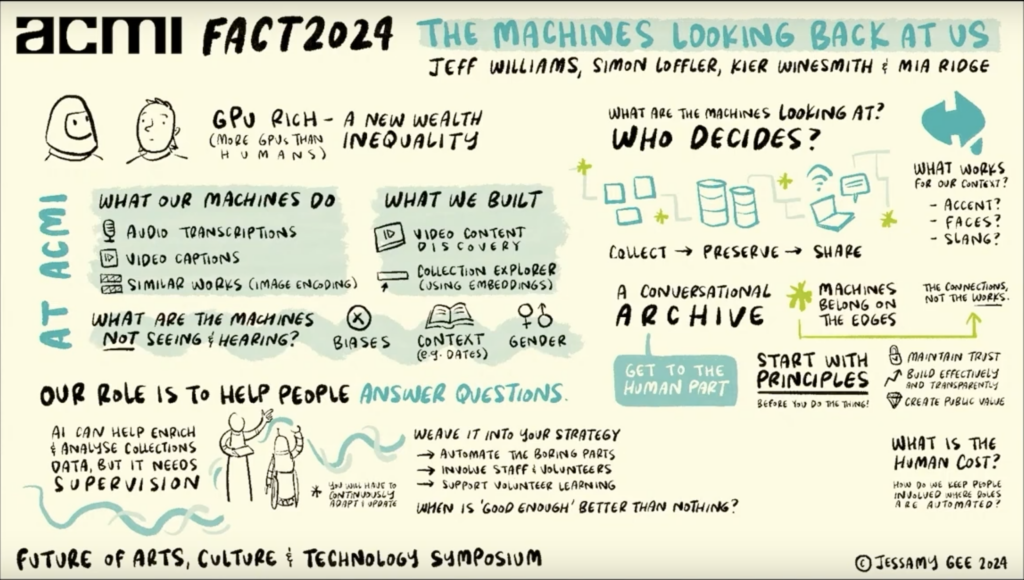
I was in Australia (Melbourne, Ballina, Brisbane) in February-March. In February 2024 I took part in a panel on 'The Machines looking back at us' at the Future of Arts, Culture & Technology Symposium (FACT 2024) at ACMI, in Melbourne, Australia.
The videos from ACMI's FACT symposium are up on their website, with automatic transcripts for each session. My presentation is here in the longer panel session; you can also watch Jessamy Gee's graphic notation from the session being created in real time.
I presented at the State Library of Victoria for a 'Digital Salon' on 'Technology & Experimentation: From the Lab to the Library’ on February 19.
On Feb 27 I spoke online at AI4LAM’s Australia and Aotearoa New Zealand chapter webinar on ’Models for Collaboration – GLAM and ML/AI Technologies’.
The video of my keynote, 'Evolutionary Innovations: Collections as Data in the AI era' for Making Meaning 2024 at the State Library of Queensland in March is now online.
Straight into work when I got back to the UK for our British Library / Guardian collaboration on 'Safeguarding Tomorrow: The impact of AI in media & information industries'. I was on a panel on 'messy data in the age of “intelligent” machines' at Jisc DigiFest (online) the same week.
In April I gave a keynote on 'Machine Learning for Collections' at the University of Cambridge Cultural Heritage Data School, and had a great time talking to the students and staff there. I'll also spoke at an event for the Association for Manuscripts and Archives in Research Collections (AMARC).
In May, videos about the Living with Machines projects were published, including Living with Machines: Exhibition and Living with Machines: Crowdsourcing.
In early June I travelled to Dundee, Scotland as one of the CILIPS Annual Conference 2024 keynotes. A brief immersion in the world of Scottish libraries was a refreshing diversion from the ongoing issues at work. My keynote, 'Playing with boundaries: collections, crowdsourcing and machines' is now online. I blogged about 'Outreach and marketing for crowdsourcing tasks' for the Living with Machines site (the project had finished, but it was the easiest way to make the work citeable).
I was in DC / Virginia in early August for Digital Humanities 2024 (DH2024). On Tuesday I participated in a pre-conference workshop 'Teaching Machine Learning in the Digital Humanities'; on Thursday I was on a panel 'Reinventions and Responsibilities in the Age of AI' and did a poster: 'Treasures on an island? Challenges for integrating volunteer and AI-enriched metadata into GLAM systems' on the Friday.
I was in Luxembourg September 3 – 6 for the International Federation of Public History (IFPH)'s annual conference, presenting with Charlie Morgan on oral histories and AI in libraries.
I was in Kraków for "Converging Realms: Law, Technology, and Society in the Age of Ethical and Multi-Agent AI" 26-27 September, 2024 then travelled overland across Poland and Sweden to Göteborg to keynote at DigiKult on 1 – 3 October.
On November 5th I convened a panel on 'AI in Libraries: Beyond the Hype' for Libraries in Leeds, and blogged about 'Collaborating to improve usability: the Universal Viewer project' with Scott Jenson.
In December I was at the British School at Athens for a talk on libraries and AI. I wrote blog posts on AI (and machine learning, etc) with British Library collections and 'Open cultural data – an open GLAM perspective at the British Library'.
